
The Birth of a New Era of Distributed Collective Intelligence
Published:
Flexible compute usually means scaling up. More GPUs, bigger clusters, elastic cloud provisioning. The assumption is that more hardware = better results, and that the way to participate meaningfully is to have access to serious resources.
But there’s another dimension to flexibility that gets overlooked. Not just scaling the hardware, but scaling the effort across people and machines, regardless of what each one has.
When you’re optimizing something, a model, a system, a process, you’re usually doing it alone, on whatever hardware you have. But what if you could share the problem with others, pool your efforts, and optimize together? Each person’s improvements become starting points for the next, regardless of what machine they’re running on.
Not distributed compute in the traditional sense, but distributed optimization. A shared candidate pool where anyone can pull a problem, improve it, and push the result back. The system routes effort to wherever it’s most productive, and everyone’s work compounds.
I built an initial framework for this and tested it on OpenAI’s Parameter Golf challenge, deliberately on a M4 MacBook Air (16GB), the most constrained Apple Silicon, as opposed to the intended 8xH100 setup. If the idea holds, the hardware shouldn’t matter much.
The setup: share a pool of candidate solutions. An AI researcher agent runs an autoresearch loop. A bandit selects which candidate to improve, trains it for 10 minutes, evaluates, keeps improvements, reverts regressions. Periodically scan for new candidates from other participants and add them to the pool. Share improved configs back.
Everyone’s work compounds.
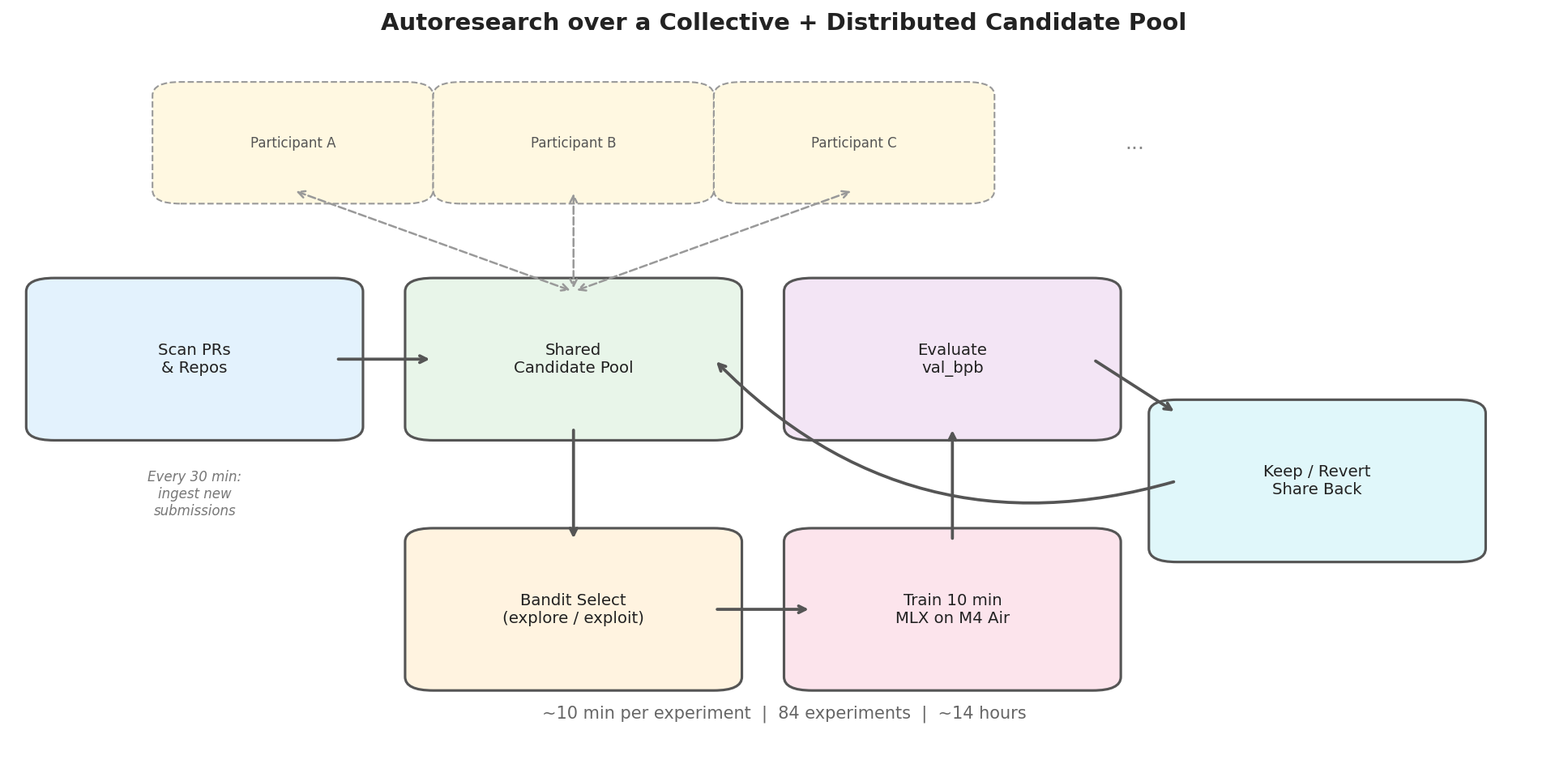
84 experiments over ~14 hours, across 14 candidates, 6 of which were ported directly from other participants’ submissions. It was the best submission in its compute category at time of submission.
Three phases emerged naturally, without being designed for:
Environment-specific fixes (3.2 → 2.1 bpb). The baseline was configured for H100s. The warmdown schedule was decaying the learning rate from step 1. Fixing this single parameter was worth -0.98 bpb, the biggest win of the entire run. Reducing batch size to fit more training steps in the wallclock budget was the second.
Hyperparameter tuning (2.1 → 1.98 bpb). Learning rate, momentum, sequence length. Systematic but diminishing returns.
Architecture changes (1.98 → 1.93 bpb). SwiGLU activation and mirrored recurrence (weight sharing across layers) broke through the hyperparameter plateau.
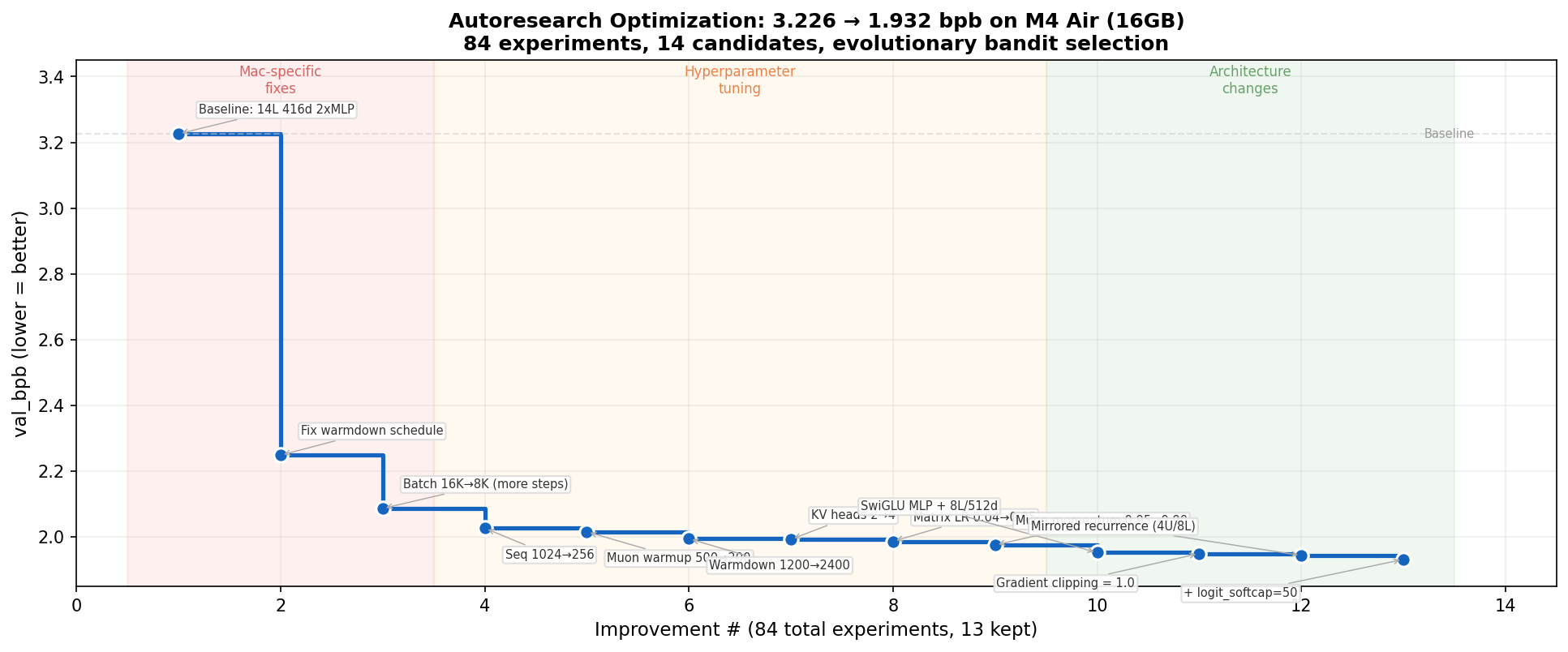 Scores from partial validation used during iteration for speed. Full eval: val_bpb=1.9263.
Scores from partial validation used during iteration for speed. Full eval: val_bpb=1.9263.
The most interesting result wasn’t any single technique. It was cross-pollination.
SwiGLU was discovered on one candidate. Mirrored recurrence was found on another, ported from PR #84. Neither was the best on its own. Combining them on a third candidate beat both.
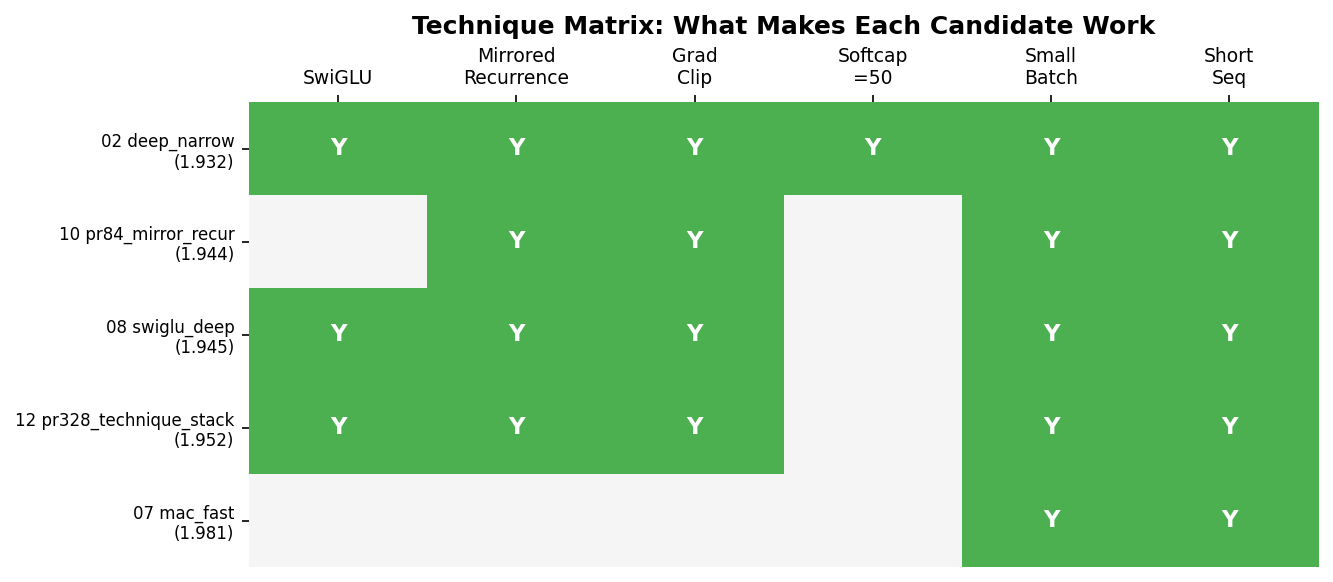
The winning candidate was the only one combining all the winning techniques, and it found them by having access to a diverse pool where good ideas could be identified and recombined. You don’t need a single brilliant run. You need a diverse pool where improvements from different sources compose.
One person, one MacBook, overnight. But there’s nothing about it that requires this.
If multiple people shared their optimization problems into collective pools, each pulling from and contributing back, improvements would compound across participants. You don’t even need the same hardware. Someone on a laptop explores one part of the space, someone on a cluster explores another, and the system routes effort to wherever it’s most productive.
That’s what flexible compute should actually mean. Not elastic provisioning of more of the same, but a system where different people, different hardware, and different ideas compound into something none of them would reach alone.
Working on some immediate improvements to this, useful here and importantly beyond:
- Evolving meta-strategy, hyperagents-style, where the search strategy itself adapts.
- Actively partitioning agent effort to suit strengths and reduce token use. Hyperparameter optimization, for instance, need not be agent-driven when other HPO methods are stronger and more efficient in this search.
- Expanding and testing the collective candidate pool with other players and collaborators, who can have their own self-improvement setups.
Full submission with all configs: PR #597
Appendix: What worked and what didn’t (Parameter Golf)
Worked: smaller batches = more steps (the single most important insight for constrained hardware), mirrored recurrence (4 unique blocks reused across 8 layers, halves parameters while maintaining effective depth), SwiGLU over relu² (consistent improvement across every candidate), and the bandit itself (correctly concentrated 41 of 84 experiments on the eventual winner).
Didn’t work: deeper models (too slow per step), very small batches (gradient noise outweighs step count benefit), BigramHash and ValueResidual (added complexity without clear gain on constrained hardware).