
The Birth of a New Era of Distributed Collective Intelligence
Published:
Most ML competitions work the same way. People take a baseline, optimize in isolation, submit. The work of one participant doesn’t directly feed into the work of another. Everyone starts from roughly the same place and branches off independently.
This has always struck me as wasteful. The submissions are open. They’re reproducible. They’re scored on the same metric. All the ingredients for compounding are there — it’s just that nobody closes the loop.
What if competition submissions weren’t isolated attempts, but a collective + distributed candidate pool that everyone improves together?
I tested this idea on OpenAI’s Parameter Golf challenge, further constraining it to 10 minutes on a M4 MacBook Air (16GB) — as opposed to the intended 8xH100 setup. It was the best submission in its compute category at time of submission.
The setup: instead of optimizing alone, pull in other participants’ PR submissions as candidates. Run a bandit over this collective pool — explore new candidates, exploit the best ones. Train each for 10 minutes, evaluate, keep improvements, revert regressions. Every 30 minutes, scan for new submissions and add them to the pool. Share improved configs back.
Everyone’s work compounds.
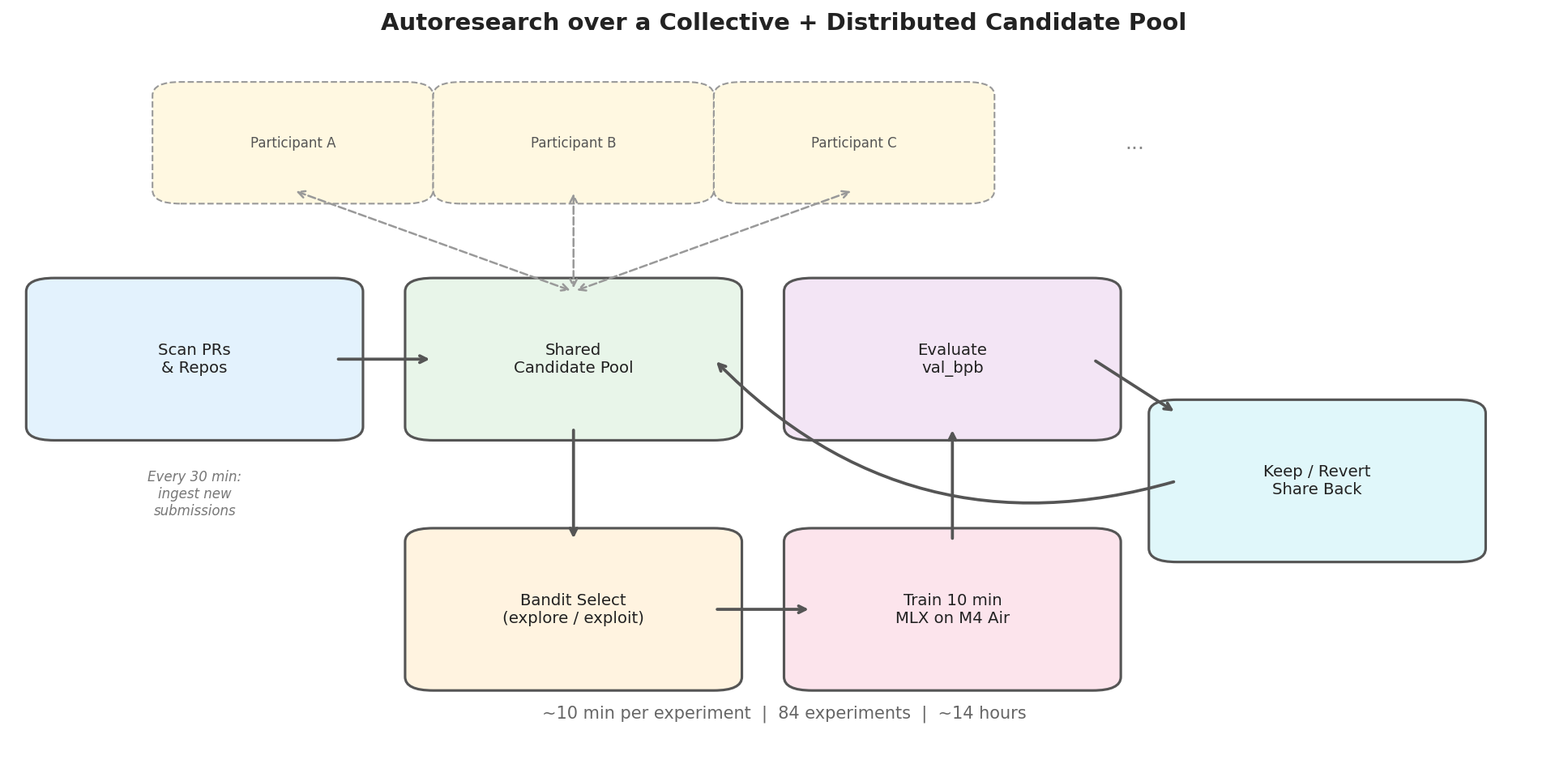
An AI researcher agent runs this loop autonomously. 84 experiments over ~14 hours, across 14 candidates — 6 of which were ported directly from other participants’ PRs.
Three phases emerged naturally, without being designed for:
Mac-specific fixes (3.2 → 2.1 bpb). The baseline was configured for H100s. The warmdown schedule was decaying the learning rate from step 1 — fixing this single parameter was worth -0.98 bpb, the biggest win of the entire run. Reducing batch size to fit more training steps in the wallclock budget was the second.
Hyperparameter tuning (2.1 → 1.98 bpb). Learning rate, momentum, sequence length. Systematic but diminishing returns.
Architecture changes (1.98 → 1.93 bpb). SwiGLU activation and mirrored recurrence — weight sharing across layers — broke through the hyperparameter plateau.
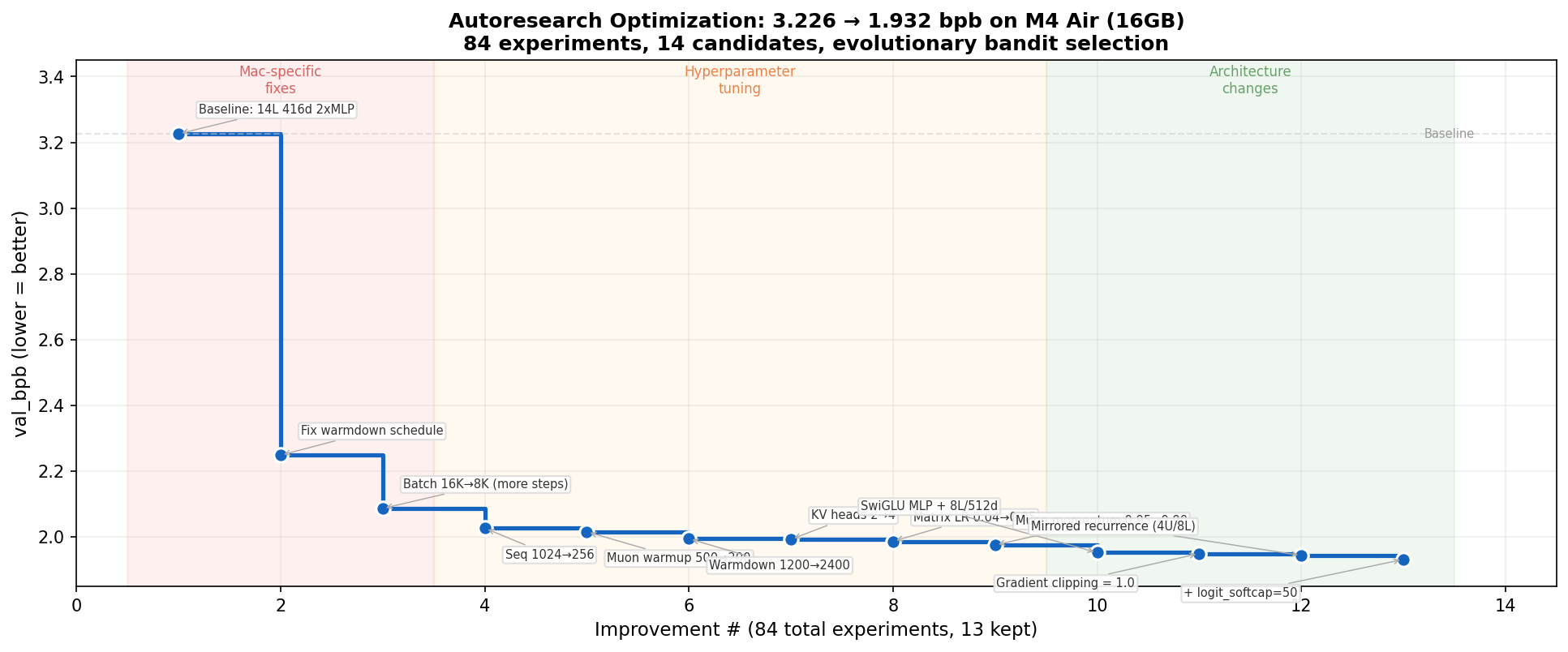 Scores from partial validation used during iteration for speed. Full eval: val_bpb=1.9263.
Scores from partial validation used during iteration for speed. Full eval: val_bpb=1.9263.
The standout finding was cross-pollination.
SwiGLU was discovered on one candidate. Mirrored recurrence was found on another, ported from PR #84. Neither was the best on its own. But combining them on a third candidate beat both.
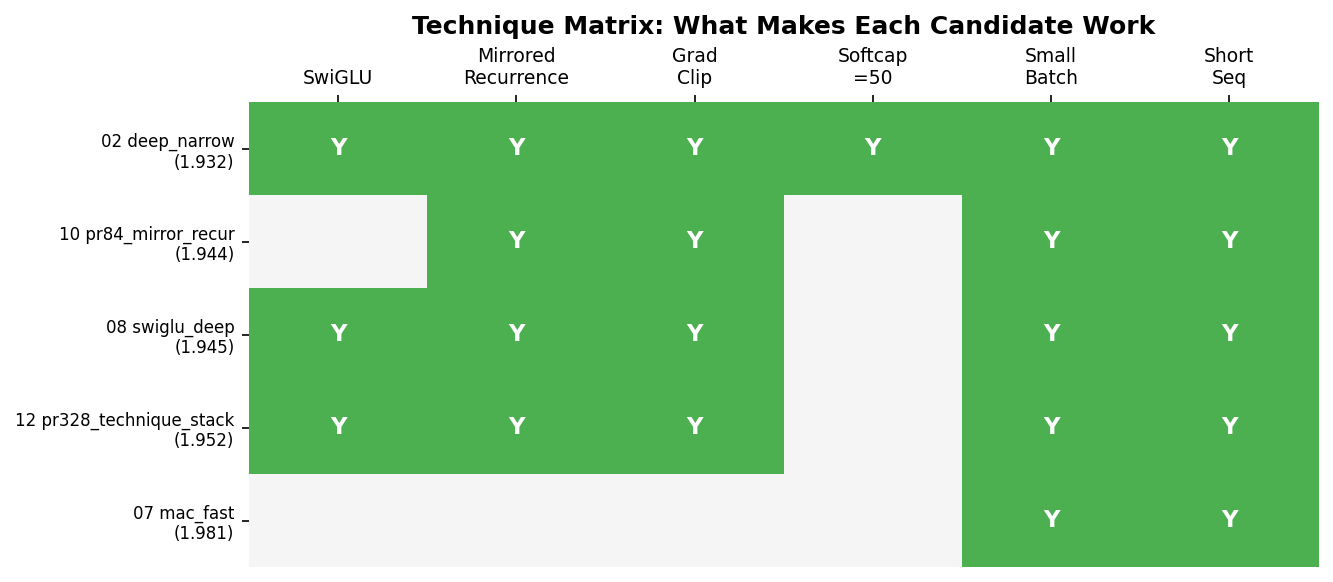
The winning candidate was the only one combining all the winning techniques. And it found those techniques by having access to a diverse pool where good ideas could be identified and recombined. You don’t need a single brilliant run. You need a diverse pool where improvements from different sources compose.
This is what excites me about the broader picture.
The setup I ran was one person, one MacBook, overnight. But there’s nothing about it that requires this. If multiple participants ran their own autoresearch loops — each pulling from and contributing back to a shared candidate pool — improvements would compound across participants. You don’t even need the same hardware. Someone on a Mac Mini explores one part of the space, someone on an A100 explores another, and the bandit routes effort to wherever it’s most productive.
This line of pooled effort gives new meaning to flexible distributed compute. The competition PR structure already provides most of what’s needed — open, reproducible, scored on the same metric. The missing piece is just the loop.
Some things that worked, and some that didn’t.
Worked: smaller batches = more steps (the single most important Mac insight), mirrored recurrence (4 unique blocks reused across 8 layers — halves parameters, maintains effective depth), SwiGLU over relu² (consistent improvement across every candidate), and the bandit itself (correctly concentrated 41 of 84 experiments on the eventual winner).
Didn’t work: deeper models (too slow per step on Mac), very small batches (gradient noise outweighs step count), BigramHash and ValueResidual (added complexity without clear gain on constrained hardware).
Working on some immediate improvements to this setup, which should be useful in competitions and importantly beyond:
- Evolving meta-strategy — hyperagents-style, where the search strategy itself adapts.
- Actively partitioning agent effort to suit strengths and reduce token use. Hyperparameter optimization, for instance, need not be agent-driven when other HPO methods are stronger and more efficient in this search.
- Expanding and testing the collective candidate pool with other players and collaborators, who can have their own self-improvement setups.
Full submission with all configs: PR #597